Whisper Code Review — Dissecting the Internal Structure of OpenAI’s STT Model
OpenAI’s Whisper is an open-source Speech-to-Text (STT) model. On the surface, it may seem like “just a model that converts speech to text,” but when you look at the code, it’s closer to a Transformer-based multimodal inference engine. In this post, we’ll dive deep into Whisper’s code and dissect its architecture.
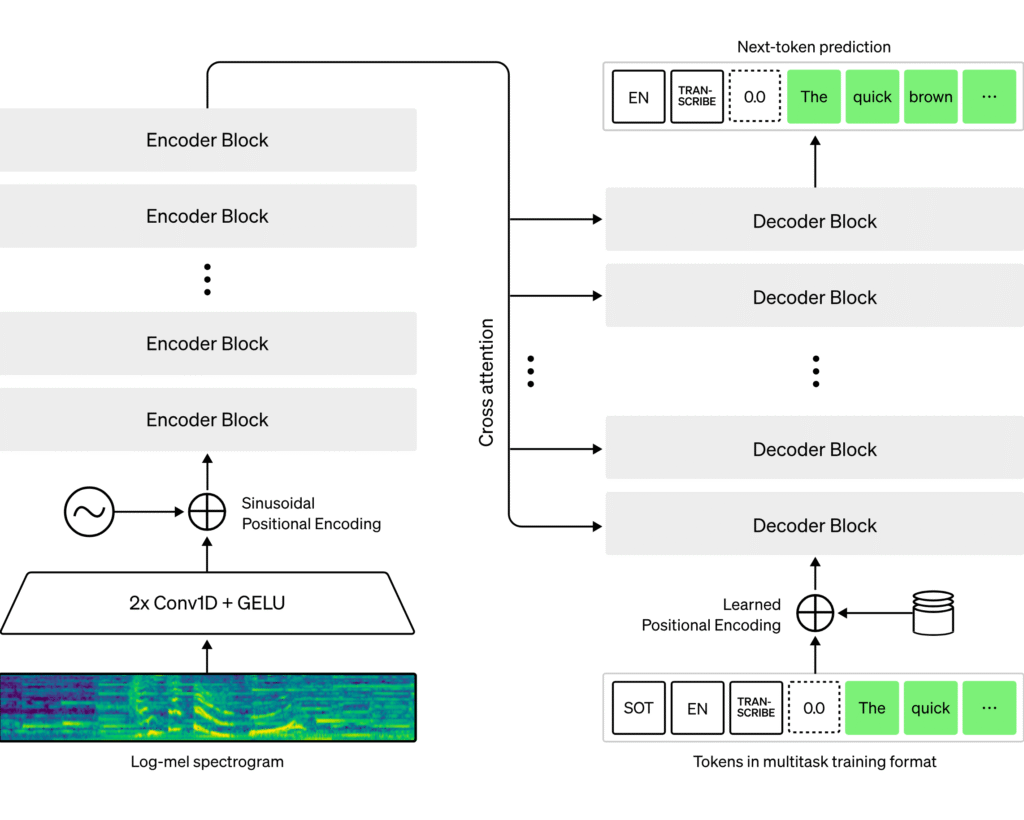
🎯 1. Overall Architecture Overview
The core of the Whisper repository lies in just 3 files:
model.py — Model definition (Transformer encoder-decoder)
audio.py — Audio preprocessing (FFT, mel spectrogram)
transcribe.py — Actual inference pipeline
Thanks to this simple structure, Whisper is one of the most readable PyTorch codebases.
🎧 2. Audio Processing Pipeline (audio.py)
Let’s first look at the audio processing part.
| |
Key Points:
Whisper normalizes all input audio to 16kHz mono float32.
It directly calls ffmpeg to support various formats.
The output is a float32 numpy array in the [-1, 1] range.
Next is the mel spectrogram conversion.
| |
What’s important here is that it generates an 80-channel Mel spectrogram. This serves as the encoder input tokens for Whisper — essentially treating audio “like an image.”
🧠 3. Model Definition (model.py)
The core of Whisper is the Transformer. Looking at the code, it’s almost a GPT-style decoder paired with a BERT-style encoder.
| |
🎙️ Encoder
AudioEncoder takes the Mel spectrogram as input and creates a latent representation.
| |
This structure repeats Conv → Self-Attention, extracting temporal features to create “audio context vectors.”
✍️ Decoder
TextDecoder is almost identical to GPT. The difference is that it references audio encoding through Cross-Attention.
| |
In other words, Whisper is “GPT that predicts sentences while looking at audio.”
⚙️ 4. Inference Pipeline (transcribe.py)
The entire pipeline is this simple:
| |
Just three steps:
Audio load + Mel conversion
Transformer encoding + decoding
Decode tokens to text
When beam search, temperature, language detection, and other options are added, you get features like --task translate, --temperature 0.2 used in Whisper CLI.
🌍 5. Multilingual Support
One of Whisper STT’s greatest strengths is multilingual recognition. The model supports over 98 languages and includes automatic language detection. This means the model can determine the input audio language without prior specification and convert it to text.
At the code level, the language parameter and --task transcribe option enable this. Thanks to the multilingual data the model was trained on, it shows high accuracy in various languages beyond English, including Spanish, Chinese, and Korean.
⚡6. Whisper.cpp Porting
While the Whisper model is PyTorch-based, there’s a C++ ported project called Whisper.cpp. Main advantages:
Fast inference even in CPU environments
Executable on mobile and embedded devices
Usable without PyTorch installation
In fact, Whisper.cpp has maximized speed and efficiency by applying various techniques such as quantization and memory optimization. It’s an excellent alternative when you want to use Whisper STT on local devices rather than servers.
💡 7. Whisper’s Design Philosophy
Reading through the code, you can feel the Whisper team’s philosophy:
Simple > Clever — Consistent design over complex tricks
Modularized pipeline — Audio → Mel → Encoder → Decoder → Text
End-to-End Differentiable — End-to-end design including preprocessing
Whisper is a best practice for “how to implement a large model with a simple structure.” This has resulted in a codebase that’s easy to read and maintain relative to its model size.
🏁 8. Conclusion
Whisper STT’s code can be called “the standard textbook of STT.” The entire process of converting speech to text using Transformers is contained in a concise and intuitive manner. Thanks to multilingual support and Whisper.cpp porting, its application range is also wide.
📚 If you want to dig deeper:
How is Beam Search implemented in Whisper
Whisper model’s multilingual processing approach
Optimization comparison between Whisper.cpp and MLX ported versions